Visarga
In-game article clicks load inline without leaving the challenge.
In Sanskrit phonology, visarga (IPA: [ʋisɐrɡɐ(hɐ)]) is the name of the voiceless glottal fricative, written in Devanagari as ⟨ः⟩ /h/. It was also called, equivalently, visarjanīya by earlier grammarians. The word visarga (Sanskrit: विसर्ग) literally means "sending forth, discharge".
Visarga is an allophone of /r/ and /s/ in pausa (at the end of an utterance). Since /-s/ is a common inflectional suffix (of nominative singular, second person singular, etc.), visarga appears frequently in Sanskrit texts. In the traditional order of Sanskrit sounds, visarga and anusvāra appear between vowels and stop consonants.
The precise pronunciation of visarga in Vedic texts may vary between Śākhās. Some pronounce a slight echo of the preceding vowel after the aspiration: aḥ will be pronounced [ɐhᵄ], and iḥ will be pronounced [ihⁱ]. Visarga is not to be confused with colon.
| Transliteration | Symbol |
|---|---|
| ISO 15919 / IAST | ⟨ḥ⟩ |
| Harvard-Kyoto | ⟨H⟩ |
Types
The visarga is commonly found in writing, resembling the punctuation mark of colon or as two tiny circles one above the other. This form is retained by most Indic scripts.
According to Sanskrit phonologists, the visarga has two optional allophones: the jihvāmūlīya (जिह्वामूलीय, the velar visarga) and the upadhmānīya (उपध्मानीय, the labial visarga). The former may be pronounced before ⟨क⟩ and ⟨ख⟩, while the latter may be pronounced before ⟨प⟩ and ⟨फ⟩. Generally, jihvāmūlīya and upadhmānīya are not rendered distinctively from the visarga, though the glyphs ⟨ᳵ⟩ and ⟨ᳶ⟩ have occasionally been used in Devanagari for that purpose; sometimes, the ardhavisarga (अर्धविसर्ग, 'half-visarga') ⟨ᳲ⟩ is used for both. Similar glyphs are found in Brahmi, Kannada, Tibetan, Sharada, and Lantsa. Examples:
- तव पितामहः कः or तव पितामहᳵ कः (tava pitāmahaẖ kaḥ?; 'who is your grandfather?')
- पक्षिणः खे उड्डयन्ते or पक्षिणᳵ खे उड्डयन्ते (pakṣiṇaẖ khe uḍḍayante; 'birds fly in the sky')
- भोः पाहि or भोᳶ पाहि (bhoḫ pāhi; 'sir, save me')
- तपःफलम् or तपᳶफलम् (tapaḫphalam; 'result of penances')
Other Brahmic scripts
Bengali
In the Bengali script, the visarga is written as ঃ and is known as bisarga (বিসর্গ). In Bengali it represents a weak post-vocalic release rather than a clearly articulated /h/ sound. Although it originates from Sanskrit final r- and s-sounds, modern Bengali preserves it primarily as an orthographic element, with its phonetic value varying according to position and environment.
Phonetic behaviour
When occurring medially within a word, the bisarga no longer produces a distinct aspiration; instead it tends to reinforce or lengthen the following consonant. Examples include দুঃস্বপ্ন or নিঃশ্বাস, where the bisarga historically reflects Sanskrit ः, but in Bengali the release is replaced by consonant strengthening or an increased sibilant effect.
When occurring finally at the end of a word, the bisarga marks an etymological aspiration inherited from Sanskrit, but in contemporary Bengali it is realised only as a very faint breath or is silent. Forms such as তঃ or যঃ illustrate this weakened contrast. Overall, Bengali pronunciation treats the visarga not as an independent consonant but as a modifier whose audible effect ranges from minimal to null.
Visarga Sandhi
In sandhi environments, the bisarga undergoes several regular transformations that depend on the nature of the following sound. These changes reflect its Sanskritic origins and are largely systematic in Bengali spelling, even when their phonetic effect is weak.
Before vowels, the bisarga commonly yields র or produces an ও-glide, preserving the historical continuity of r-final forms (e.g. পুনরধিকার). Before sibilants and coronal or palatal stops, it assimilates to the following consonant as the appropriate sibilant—শ, ষ, or স—a process that accounts for forms such as নিঃচয় → নিশ্চয়.
When followed by voiced consonants or semivowels, r-jāt bisarga typically appears as র, while s-jāt bisarga may produce an ও-transition; thus অন্তঃগত surfaces as অন্তর্গত. If the following consonant is র, the bisarga disappears entirely and the preceding vowel lengthens, as seen in নীরস. After the vowels ই or উ and before velar or labial stops, the bisarga may appear as ষ, producing forms such as নিষ্কাম.
Some compounds retain the written bisarga without any phonological modification, as in মনঃক্ষুণ্ণ. In other cases, the bisarga may be lost without affecting adjacent sounds, as in অতএব from অতঃ + এব. As a whole, visarga sandhi in Bengali reflects historical Sanskritic patterns that are preserved orthographically even though their phonetic realisation is limited in modern speech.
Burmese
In the Burmese script, the visarga (variously called ရှေ့ကပေါက် shay ga pauk, ဝစ္စနစ်လုံးပေါက် wizza nalone pauk, or ရှေ့ဆီး shay zi and represented with two dots to the right of the letter as း), when joined to a letter, creates the high tone.
Japanese
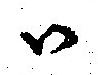
Motoori Norinaga invented a mark for visarga which he used in a book about Indian orthography.
Javanese
In the Javanese script, the visarga, known as the wignyan (ꦮꦶꦒ꧀ꦚꦤ꧀), is represented by two curls to the right of a syllable as ꦃ: the first curl is short and circular, and the second curl is long. It adds a /-h/ after a vowel.
Kannada
In the Kannada script, the visarga (which is called visarga) is represented with two small circles to the right of a letter ಃ. It adds an aḥ sound to the end of the letter.
This script also has separate symbols for ardhavisarga absent in most other scripts, jihvamuliya, ೱ, and upadhmaniya, ೲ.
Khmer
In the Khmer script, the visarga (known as the reăhmŭkh (រះមុខ; "shining face")) indicates an aspirated /ʰ/ sound added after a syllable. It is represented with two small circles at the right of a letter as ះ, and it should not be confused with the similar-looking yŭkôlpĭntŭ (យុគလពិន្ទុ; "pair of dots"), which indicates a short vowel followed by a glottal stop like their equivalent visarga marks in the Thai and Lao scripts.
Lao
In the Lao script, the visarga is represented with two small curled circles to the right of a letter as ◌ະ. As in the neighboring related Thai script, it indicates a glottal stop after the vowel.
Malayalam
In the Malayalam script, the visarga is represented with two small circles to the right of a letter as ഃ. It indicates a /h/ after a letter. Visarga is considered as a vowel in Malayalam, where its independent form is written as അഃ. Unlike other languages, visarga need not necessarily occur at the end of a word. Examples include ദുഃഖം, മനഃപ്രയാസം, പുനഃസൃഷ്ടി.
Odia
In the Odia script, the Bisarga is represented with a vertical infinity sign to the right of a letter as ଃ. It indicates the post-vocalic voiceless glottal fricative aḥ [h] sound after the letter, Unlike other languages, the bisarga can appear in middle of words, such as ନିଃଶ୍ବାସ, ନିଃସ୍ବ, ନିଃସନ୍ଦେହ, ନିଃଶେଷ etc. All words with Bisarga aren't borrowed from Sanskrit.
Sinhala
In the Sinhala script, visarga is represented with two small circle to the right of a letter as ඃ.
Tamil
In the Tamil script, similar to visarga (which is called āyuta eḻuttu (ஆயுத எழுத்து), āytam (ஆய்தம்), muppāl puḷḷi, taṉinilai, aḵkēṉam, ak), transliterated as ḵ, is represented with three small circles to the right of a letter as ஃ. Its used to transcribe an archaic /h/ sound inherited from the proto Dravidian *H that has either become silent or geminates the next letter in unlearnt speech, or pronounced as /k/ or /h/ in careful speech. Like Sanskrit, it cannot add on to any letter and add aspiration to them. It should be always placed between a single short vowel and a hard consonant (க், ச், ட், த், ப், ற்) for example அஃது (aḵtu), எஃகு (eḵku). The āytam in modern Tamil is used to transcribe foreign phones like ஃப் (ஃp) for [f], ஃஜ (ஃj) for [z], ஃஸ (ஃs) for [z, ʒ] and ஃக (ஃk) for [x], similar to a nuqta.
Telugu
In the Telugu script, there are two visargas. One is represented with two small circles to the right of a letter ః. It brings an "ah" sound to the end of the letter.
Thai
In the Thai script, the visarga (known as the visanchani (วิสรรชนีย์) or nom nang thangkhu (นมนางทั้งคู่)) is represented with two small curled circles to the right of a letter as ◌ะ. It represents a glottal stop that follows the affected vowel.
Unicode
Unicode encodes visarga and visarga-like characters for a variety of scripts:
| Script | Sign | Example | Unicode |
|---|---|---|---|
| South Asian scripts Script Sign Example Unicode Bengali ঃ কঃ U+0983 Bhaiksuki 𑰾 𑰎𑰾 U+11C3E Brahmi 𑀂 𑀓𑀂 U+11002 Chakma 𑄂 𑄇𑄂 U+11102 Devanagari ः कः U+0903 Dogra 𑠸 𑠊𑠸 U+11838 Grantha 𑌃 𑌕𑌃 U+11303 Gujarati ઃ કઃ U+0A83 Gunjala Gondi 𑶖 𑵱𑶖 U+11D96 Gurmukhi ਃ ਕਃ U+0A03 Gurung Khema U+1612E Kaithi 𑂂 𑂍𑂂 U+11083 Kannada ಃ ಕಃ U+0C83 Kharosthi 𐨏 𐨐𐨏 U+10A0F Malayalam ഃ കഃ U+0D03 Masaram Gondi 𑵁 𑴌𑵁 U+11D41 Modi 𑘾 𑘎𑘾 U+1163E Mongolian ᢁ᠋ ᢁ᠋ᠠ᠋ U+1881 Nandinagari 𑧟 𑦮𑧟 U+119DF Odia ଃ କଃ U+0B03 Prachalit Nepal 𑑅 𑐎𑑅 U+11445 Sharada 𑆂 𑆑𑆂 U+11183 Saurashtra ꢁ ꢒꢁ U+A881 Siddham 𑖾 𑖎𑖾 U+115BE Sinhala ඃ කඃ U+0D83 Soyombo 𑪗 𑩜𑪗 U+11A97 Takri 𑚬 𑚊𑚬 U+116AC Tamil ஃ கஃ U+0B83 Telugu ః కః U+0C03 Tibetan (rnam bcad) ཿ ཀཿ U+0F7F Tirhuta 𑓁 𑒏𑓁 U+114C1 Zanabazar Square 𑨹 𑨋𑨹 U+11A39 | Southeast Asian scripts Script Sign Example Unicode Balinese (bisah) ᬄ ᬓᬄ U+1B04 Burmese း ကး U+1038 Javanese (wignyan) ꦃ ꦏꦃ U+A983 Kawi 𑼃 𑼒𑼃 U+11F02 Khmer (reahmuk) ះ កះ U+17C7 Lao ະ ກະ U+0EB0 Sundanese (pangwisad) ◌ᮂ ᮊᮂ U+1B83 Thai (visanchani) ะ กะ U+0E30 | ||
| Bengali | ঃ | কঃ | U+0983 |
| Bhaiksuki | 𑰾 | 𑰎𑰾 | U+11C3E |
| Brahmi | 𑀂 | 𑀓𑀂 | U+11002 |
| Chakma | 𑄂 | 𑄇𑄂 | U+11102 |
| Devanagari | ः | कः | U+0903 |
| Dogra | 𑠸 | 𑠊𑠸 | U+11838 |
| Grantha | 𑌃 | 𑌕𑌃 | U+11303 |
| Gujarati | ઃ | કઃ | U+0A83 |
| Gunjala Gondi | 𑶖 | 𑵱𑶖 | U+11D96 |
| Gurmukhi | ਃ | ਕਃ | U+0A03 |
| Gurung Khema | | | U+1612E |
| Kaithi | 𑂂 | 𑂍𑂂 | U+11083 |
| Kannada | ಃ | ಕಃ | U+0C83 |
| Kharosthi | 𐨏 | 𐨐𐨏 | U+10A0F |
| Malayalam | ഃ | കഃ | U+0D03 |
| Masaram Gondi | 𑵁 | 𑴌𑵁 | U+11D41 |
| Modi | 𑘾 | 𑘎𑘾 | U+1163E |
| Mongolian | ᢁ᠋ | ᢁ᠋ᠠ᠋ | U+1881 |
| Nandinagari | 𑧟 | 𑦮𑧟 | U+119DF |
| Odia | ଃ | କଃ | U+0B03 |
| Prachalit Nepal | 𑑅 | 𑐎𑑅 | U+11445 |
| Sharada | 𑆂 | 𑆑𑆂 | U+11183 |
| Saurashtra | ꢁ | ꢒꢁ | U+A881 |
| Siddham | 𑖾 | 𑖎𑖾 | U+115BE |
| Sinhala | ඃ | කඃ | U+0D83 |
| Soyombo | 𑪗 | 𑩜𑪗 | U+11A97 |
| Takri | 𑚬 | 𑚊𑚬 | U+116AC |
| Tamil | ஃ | கஃ | U+0B83 |
| Telugu | ః | కః | U+0C03 |
| Tibetan (rnam bcad) | ཿ | ཀཿ | U+0F7F |
| Tirhuta | 𑓁 | 𑒏𑓁 | U+114C1 |
| Zanabazar Square | 𑨹 | 𑨋𑨹 | U+11A39 |
| Script | Sign | Example | Unicode |
| Balinese (bisah) | ᬄ | ᬓᬄ | U+1B04 |
| Burmese | း | ကး | U+1038 |
| Javanese (wignyan) | ꦃ | ꦏꦃ | U+A983 |
| Kawi | 𑼃 | 𑼒𑼃 | U+11F02 |
| Khmer (reahmuk) | ះ | កះ | U+17C7 |
| Lao | ະ | ກະ | U+0EB0 |
| Sundanese (pangwisad) | ◌ᮂ | ᮊᮂ | U+1B83 |
| Thai (visanchani) | ะ | กะ | U+0E30 |